Isaac Kargar






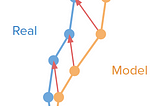
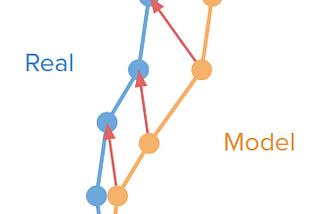
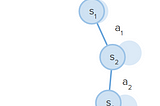
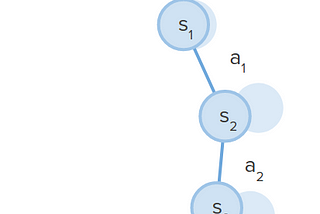




Isaac Kargar
Co-Founder and CIO @ Resoniks | Ph.D. candidate at the Intelligent Robotics Group at Aalto University | https://kargarisaac.github.io/
Co-Founder and CIO @ Resoniks | Ph.D. candidate at the Intelligent Robotics Group at Aalto University | https://kargarisaac.github.io/